人工智能的应用正在迅速成为我们高度互联的世界的关键,这得益于生成式人工智能的不断增长的需求。根据 Futurum Intelligence 的数据,数据中心领域用于处理器和加速器的 AI 芯片组市场在 2023 年的价值为 380 亿美元,预计将以 30% 的复合年增长率增长,到 2028 年将达到 1380 亿美元。这一增长源于生成式 AI 模型的快速采用,以及芯片制造商对优化 AI 推理芯片支持的关注。
GPU 在数据中心 AI 市场上占据主导地位,持有 92% 的市场份额,占数据中心使用的人工智能芯片组的 74%。由英伟达等公司引领的 GPU 市场预计将以 30% 的复合年增长率增长,到 2028 年将达到 1020 亿美元。CPU 也在人工智能处理中发挥关键作用,预计复合年增长率为 28%,从 2023 年的 77 亿美元增长到 2028 年的 260 亿美元。谷歌和 AWS 等超大规模云提供商是人工智能芯片组采购的主要驱动力,在 2023 年占有 43% 的市场份额,预计到 2028 年将增长至 50%。包括 Google TPU 和 AWS Trainium 在内的定制云加速器在扩展人工智能基础设施方面越来越重要。
随着人工智能芯片组需求的增长,关键的开发挑战也随之而来,包括平衡功耗和性能、管理有限的内存和处理资源、解决数据安全和隐私问题,以及优化连接和通信协议。此外,在低功耗设备上部署人工智能算法需要进行仔细的算法优化,以确保高效的性能。
不同架构正在被探索以实现最佳的每瓦性能。虽然CPU和GPU预计在低端使用,但更加先进的定制设计,如谷歌TPU,被部署在高端应用。然而,这些架构推动了芯片尺寸和复杂性的发展,在时序收敛、流量拥塞和功耗管理方面造成了潜在问题。因此,机器学习片上网络变得越来越重要,帮助架构师最大限度地提高性能和效率,同时管理机器学习工作负载的空间分布。
Arteris 提供了支持边缘人工智能推理的解决方案,例如 FlexNoC XL 选项,它允许开发人员创建灵活的网络架构。这些解决方案解决了关键的时序收敛问题、带宽需求和内存控制器利用率挑战,这些挑战对于在日益复杂的系统中实现高性能至关重要。
优势
可扩展性
使用高效的不同于黑匣子编译器方法,创建高度可扩展的环形、网状和环形拓扑结构,SoC 架构师可以根据需求编辑生成的拓扑结构,并优化每个单独的网络路由。
带宽
使用HBM2和多通道内存支持,多播/广播写入,VC-Link™虚拟频道以及源同步通信技术,增加片上和片间带宽。
低功耗
更少的门电路和连接线使消耗的功耗更少,将通信路径分成更小的段可以实现仅为活动的段供电,同时简单的内部协议可以实现极致的时钟门控。
创新
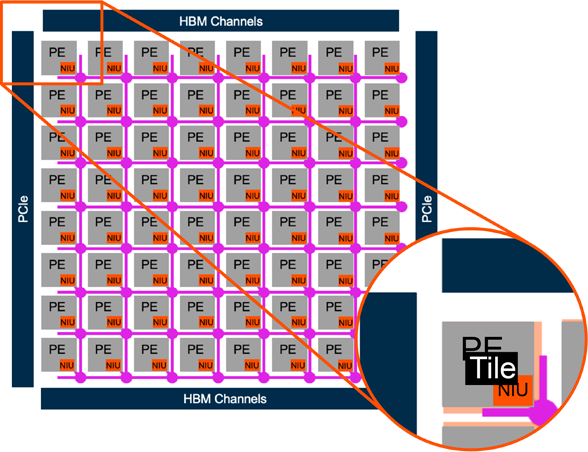
片上网络瓦格化技术加速面向人工智能应用的半导体设计
片上网络瓦格化(tiling)是 SoC 设计的新兴趋势。它使用经过验证的、稳健的片上网络 IP 来促进扩展、缩短设计时间、加快测试速度并降低设计风险。
它使 SoC 架构师能够快速创建模块化、可扩展的 AI 设计,从而实现更快的集成、验证和优化。
NoC 瓦格化优势- 适用于 FlexNoC 和 Ncore
- 可扩展性能
- 降低功耗
- 设计重用
![]()
汽车
![]()
通信
![]()
消费电子
![]()
企业计算
![]()
工业
![]()
人工智能/机器学习
边缘计算推理应用
注重模块化和层次化设计,简化布线和布局,提升面积和功耗效率
边缘计算训练和推理应用数据交互
专注于可扩展性、更简单的布线和布局
嵌入式计算推理应用
专注于面积和功耗效率
企业级培训应用
关注可扩展性和层次化设计,更易于布线和布局
边缘计算推理应用
专注于可扩展性、更简单的布线和布局
![]() 人工智能 / 机器学习
人工智能 / 机器学习
![]()
汽车
边缘计算推理应用
注重模块化和层次化设计,简化布线和布局,提升面积和功耗效率
![]()
通信
边缘计算训练和推理应用数据交互
专注于可扩展性、更简单的布线和布局
![]()
消费电子
嵌入式计算推理应用
专注于面积和功耗效率
![]()
企业计算
企业级培训应用
专注于可扩展性、更简单的布线和布局
![]()
工业
边缘计算推理应用
专注于可扩展性、更简单的布线和布局
合作伙伴
Andes Technology 作为 RISC-V 国际组织的创始成员和首要成员,是高性能/低功耗 RISC-V 处理器 IP 的领先供应商。Andes Technology 和 Arteris 合作,推动 RISC-V SoC 设计的创新,用于人工智能、5G、网络、移动、存储、AIoT 和空间应用。Andes QiLai RISC-V 开发平台是一个开发板,其中包含一个 QiLai SoC,该 SoC 采用 Andes 的 RISC-V 处理器 IP,以及 Arteris FlexNoC 互连 IP,用于片上连接。
2024年3月,Arteris与Arm合作推出了基于仿真的验证系统,用于加速汽车电子创新、支持Armv9和基于CHI-E的设计,以加快自动驾驶、高级驾驶辅助系统(ADAS)、驾驶舱和信息娱乐系统、视觉、雷达和激光雷达、车身和底盘控制、分区控制器等汽车应用领域的创新。Arteris与Arm的路线图保持一致,为设计师提供了一个经过优化和预验证的高带宽、低延迟的Ncore缓存一致互连IP,以加速Arm的汽车增强(AE)计算组合的上市速度。这一合作帮助客户实现具有高性能和低功耗的SoC,用于安全关键任务,同时缩短项目进度和降低成本。它为共同客户提供了更多安全、集成和优化的汽车解决方案选择,通过与ISO 26262系统的无缝集成和优化流程,以及最高质量的结果,实现更快的上市时间,从而实现最高汽车安全完整性级别(ASIL)。
由达摩学院(阿里巴巴集团旗下)牵头的达摩无界联盟,是一个推动 RISC-V 指令集架构采用和发展的生态联盟。该联盟专注于高性能片上系统 (SoC) 设计,特别是在边缘人工智能计算领域。作为联盟成员,Arteris 发挥着至关重要的作用,通过其 Ncore 缓存一致片上网络 (NoC) 系统 IP,实现达摩学院/T-Head 的玄铁 RISC-V 处理器 IP 内核的集成,从而在内核内和芯片之间实现高效的数据传输架构,支持人工智能、机器学习等领域的尖端应用。
弗劳恩霍夫信息与系统工程研究所 (Fraunhofer IESE) 是弗劳恩霍夫协会 (Fraunhofer- Gesellschaft) 旗下 76 家研究所和研究机构之一。这些机构共同致力于推动欧洲应用研究的进步,并提升德国在国际市场上的竞争力。我们与弗劳恩霍夫协会的合作使我们能够通过 Ncore 和 FlexNoC SystemC 仿真以及 DRAMSys DRAM 建模和仿真框架之间的连接,对 DRAM 性能对片上网络性能的影响进行早期架构分析。
Arteris和Sifive 的合作加速了用于消费电子和工业应用的边缘 AI SoCs的开发。这一合作将SiFive的多核RISC-V处理器IP与Arteris的Ncore高速缓存一致性互连IP相结合,提供高性能和功耗效率,同时减少项目进度和集成成本。该合作实现了Sifive 22G1 X280客户参考平台的开发,其中AMD Virtex Ultrascale+ FPGA VCU118评估套件上包含了的Sifive X280处理器IP和Arteris Ncore 高速缓存一致性互连IP 。
Semidynamics是完全可自定义的RISC-V处理器IP的提供商,专门开发针对机器学习和AI应用程序,具有矢量单元,标量单元和Gazzillion的高带宽,高性能核。我们的协作增强了处理器IP与System IP的灵活性和高度可配置的互操作性,旨在以加速人工智能,机器学习和高性能计算(HPC)应用程序提供集成和优化的解决方案。
- Technical Papers
- Presentations
- The Role of Networks-on-Chips Enabling AI/ML Silicon and Systems | AI Everywhere 2023
- Customers
- SiMa.ai case study – Push-Button Ease of Arteris FlexNoC Freed Up the Team to Focus on Designing The World’s First Machine Learning SoC
- Sondrel case study – Shortening Leading-Edge ADAS Design Cycles With FlexNoC To Deliver Customer Success
- Articles
- Press Releases
- Arteris Deployed by Menta for Edge AI Chiplet Platform | Dec 03,2024
- Arteris and MIPS Partner on High-Performance RISC-V SoCs for Automotive, Datacenter and Edge AI | Nov 12, 2024
- Arteris Network-on-Chip Tiling Innovation Accelerates Semiconductor Designs for AI Applications | Oct 15, 2024
- Arteris Selected by Esperanto Technologies to Integrate RISC-V Processors for High-Performance AI and Machine Learning Solutions | Jun 11, 2024
- Andes Technology and Arteris Partner To Accelerate RISC-V SoC Adoption | May 22, 2024
- Rebellions Selects Arteris for Its Next-Generation Neural Processing Unit Aimed at Generative AI | Apr 09, 2024
- Arteris Expands Automotive Solutions for Armv9 Architecture CPUs | Mar 13, 2024
- EdgeQ Deploys Arteris IP for its 5G+AI Base Station-on-a-Chip for Wireless Infrastructure | Feb 13, 2024
- Arteris Selected by Rain AI for Use in the Next Generation of AI | Jan 30, 2024
- Semidynamics and Arteris Partner To Accelerate AI RISC-V System-on-Chip Development | Nov 02, 2023
- Fraunhofer IESE Partners With Arteris To Accelerate Advanced Network-on-chip Architecture Development for AI/ML Applications | Oct 17, 2023
- Arteris Interconnect IP Deployed in NeuReality Inference Server for Generative AI and Large Language Model Applications | Oct 10, 2023
- Tenstorrent Selects Arteris IP for AI High-Performance Computing and Datacenter RISC-V Chiplets | May 02, 2023
- Arteris IP Licensed by Axelera AI to Accelerate Computer Vision at the Edge | Apr 26, 2023
- Arteris IP Selected By ASICLAND for Automotive, AI Enterprise and AI Edge SoCs | Apr 12, 2023
- Arteris and SiFive Partner to Accelerate RISC-V SoC Design of Edge AI Applications | Feb 27, 2023
- Arteris Collaborates with SiMa.ai to Optimize ML Implementation With Efficient Topology Interconnect IP for the Embedded Edge | Aug 30, 2022
- Arteris IP FlexNoC Interconnect and Resilience Package Licensed in Neural Network Accelerator Chip Project Led by BMW Group | Apr 5, 2022
- Arteris FlexNoC Interconnect Licensed by Eyenix for AI-Enabled Imaging/Digital Camera SoC | Oct 19, 2021
- Arteris FlexNoC Interconnect Licensed for use in SK Telecom SAPEON AI Chips | Sep 7, 2021
- Arteris IP FlexNoC Interconnect and Resilience Package Licensed by Hailo for Artificial Intelligence (AI) Chip | Jan 12, 2021
- Arteris FlexNoC Interconnect and AI Package Licensed by Blue Ocean Smart System for AI Chips | May 19, 2020
- Arteris FlexNoC Interconnect and AI Package Licensed by Vastai Technologies for Artificial Intelligence Chips | Jan 21, 2020
- Arteris Ncore Cache Coherent Interconnect Licensed by Bitmain for Sophon TPU Artificial Intelligence (AI) Chips | Jul 9, 2019